AGENTS.md and SKILL.md: building a reusable agent toolbox
Context engineering gets more useful when the knowledge it depends on is packaged for reuse. In this post I map the portable core (AGENTS.md and SKILL.md), Copilot-specific concepts like custom instructions, agents and prompt files, and how to decide what knowledge belongs where.
Part of: Context Engineering · Post 2 of 2 ›
- 01 Context engineering: more context isn't better context
- 02 AGENTS.md and SKILL.md: building a reusable agent toolbox
I was working on a personal project and coming up with a Copilot CLI demo to show and tell at the GitHub Social Club in London yesterday. But as I started a fresh agent session, and typed the setup, I caught myself writing the same lines I’d written for some work a few days earlier.
It included a few lines around the process for writing out plans, how the agent should hand off between planning, what the implementation expectations were, and how to review the work when it was done. That repetition (me repeatedly hitting the up arrow to get to my earlier prompts) was a sign that the knowledge I was typing should be packaged as something reusable, not left as another throwaway prompt.
In my first post on context engineering, I argued that more context isn’t the same as better context. The part I want to pick up here is from the closing section:
Instructions and capabilities lead into reusable agent skills and AGENTS.md-style files. Once you stop treating every workflow as a one-off, you start asking how to package useful behaviour so teams can share it.
To keep things concrete, I’ll thread a single example through the rest of this post: building an account settings page in a React and Tailwind app. The scenario and the stack itself don’t really matter that much. What I want to show is how the same underlying knowledge ends up packaged differently at each layer, and why that layering matters.
If these concepts are new to you, I’d recommend starting with the most portable layer that solves the problem and then adding tool-specific layers when they’re helpful.
Repetition is a context engineering signal
Imagine you sit down to build that account settings page. You might type something like this into a fresh session:
Build me an account settings page. We use React 18 with TypeScript and
Tailwind CSS. Tests go in __tests__/ beside the source files. Use vitest.
Components live in src/components/ and follow PascalCase naming. Don't add
new dependencies without asking. Use our existing Button and Input from
the design system. The page needs email, password, and notification
preferences. Make sure it's accessible, we target WCAG 2.1 AA. Oh, and
run the linter before you finish.
Most of that prompt isn’t specific to this task. The testing conventions, the naming rules, the component library and the accessibility baseline are repository knowledge. That information belongs somewhere the agent can find it without you having to type it out every time.
Some of that information may be broad enough to belong in some repository-wide instructions. Some of it may be specific enough to the types of files you’re working on, or the types of tasks that you’re completing, and need to be a little more targeted. Or, if there’s genuinely a repeatable workflow in there, it may belong as some kind of reusable prompt as a reliable starting point for that kind of work.
In other words, the prompt you’re re-entering isn’t the asset. The reusable knowledge and guidance is.
Agent sessions are temporary. You complete your task, spin up a new agent session for the next thing and start again. But without capturing that reusable knowledge, you end up repeating the same setup over and over again. Once that guidance is captured, you can apply it again without rewriting it from scratch.
For individual developers, the agent will start each session in a more useful place with less manual prompting each time. For teams, the good habits become easier to share, reuse, and improve. That’s where things start to compound.
AGENTS.md: repository-wide agent instructions
This layer tells an agent how to work in this codebase regardless of today’s task: the stack, the folder structure, the validation steps, the conventions, and the mistakes to avoid. Think of it as lightweight onboarding for an AI collaborator. (Assuming you’re not working in a monorepo, in which case you may have a few of these files to cover different subprojects or packages. But I’ll come back to that.)
Returning to the settings page example, the repo-wide knowledge from that earlier prompt could be packaged in a few ways.
Portable example: AGENTS.md
The most widely recognised portable version of this idea is AGENTS.md.
# AGENTS.md
## Stack
React 18 + TypeScript + Tailwind CSS. Vitest for unit tests.
## Project structure
- `src/components/` - UI components (PascalCase naming)
- `src/hooks/` - Custom hooks (camelCase, `use` prefix)
- `__tests__/` - Tests beside source files
## Conventions
- Prefer existing design system components (`Button`, `Input`, `Card`)
over custom styling
- Do not introduce new dependencies without explaining why
- Run `pnpm lint && pnpm test` before finishing
- Target WCAG 2.1 AA compliance for all interactive elements
The actual task (“build an account settings page”) doesn’t belong here. Instead, this file contains the knowledge that applies to any task in the repository. Tomorrow you might build a dashboard, next week a checkout flow. The conventions are the same each time.
What makes AGENTS.md useful is how easily it travels. It’s just Markdown and has no special syntax or vendor lock-in. Support exists across tools like GitHub Copilot, OpenAI Codex, Cursor, Claude Code, and more (though the level of support varies by tool, so check the docs for yours), so the same baseline can move with you as you transition between tools. That portability means you spend your time on the knowledge itself, not on which file format it lives in.
You can also nest AGENTS.md files. If you have a shared root file with the broad baseline, you can add more specific AGENTS.md files deeper in the tree for subprojects or packages. The important thing to remember is that the closest AGENTS.md to the work wins. If you’re working in services/api/, the agent will pick up services/api/AGENTS.md over the root file, so you can layer on the commands, conventions, and gotchas that only matter in that part of the codebase.
GitHub Copilot-native example: .github/copilot-instructions.md
If you’re primarily a GitHub Copilot user, then you may be familiar with Copilot Custom Instructions. The same repository-wide baseline can also live in .github/copilot-instructions.md (though Copilot also supports AGENTS.md files too).
# Copilot instructions
## Stack
React 18 + TypeScript + Tailwind CSS. Vitest for unit tests.
## Working rules
- Prefer existing design system components (`Button`, `Input`, `Card`)
over custom styling
- Do not introduce new dependencies without explaining why
- Run `pnpm lint && pnpm test` before finishing
- Target WCAG 2.1 AA compliance for all interactive elements
I see these as different packaging approaches for the same layer of repo-wide guidance. However, I wouldn’t duplicate the same baseline into both files. As we know from software development, duplication is a source of drift. Keep one as the source of truth and link to it from the other if you need to use both.
If you want the primary reference for AGENTS.md rather than my blog post, start with agents.md and the agentsmd/agents.md repository.
SKILL.md: reusable agent procedures
Repository-wide instructions are a great starting point, but they’re broad by design. What they don’t capture are reusable capabilities that should be applied only when needed. That’s where SKILL.md comes in.
The idea is that you package a useful behaviour so it can be invoked when relevant, potentially combined with other capabilities, and most importantly, reused.
Instead of saying “here is how to behave in this repository,” a skill file says “here is how to do this kind of work well.” So when we think back to our settings page, building a UI component from a design reference might be a repeatable task. We could package that workflow into a skill:
---
name: design-to-component
description: >
Convert a design artefact into a React component using the project's
design system. Use when building UI from mockups, wireframes, or
Figma exports.
---
# Design to Component
## Core procedure
1. Identify the visual elements and their interactive states
2. Map each element to existing design system primitives
(Button, Input, Card, etc.) before creating anything custom
3. Build the component with semantic, accessible markup
4. Write tests for user interactions and edge states
5. If the design references tokens not in the local system,
load `references/design-tokens.md` for the full mapping
Why skills scale: progressive disclosure
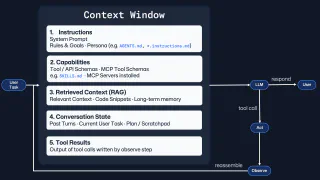
A skill file isn’t meant to be loaded in one go. Put simply, a well-behaved skill loads in stages rather than dumping everything into the context window at once. The Agent Skills specification describes this as a three-stage progressive disclosure model, and tools that implement the spec can use it to keep skill loading practical at scale. The figures and stage names below reflect the spec at time of writing, so check the spec directly if you’re implementing against it:
Metadata first (~100 tokens per skill). At startup, an agent only needs the
nameanddescriptionfrom each skill’s frontmatter. This acts as the index. If a task doesn’t match, the skill body doesn’t need to be loaded.Instructions on activation (<5,000 tokens). When a skill is relevant to the current task, the agent can load the full
SKILL.mdbody: the procedure, the gotchas, the validation expectations.Resources on demand. If the instructions reference supplementary material (scripts, design token tables, API schemas or any other assets), those can then be loaded when a specific step calls for them.
As a result, a repository can have a large number of skills without overwhelming the agent with information and bloating the context window. The agent only pays the token cost for the skills that are relevant to the current task, and even then, it only loads the full instructions when it needs them.
What makes skills work is that you can mix them together. One workflow might need a planning skill which follows your internal planning process, a testing skill that integrates with your test plans, and a documentation skill that researches across projects to ensure a consistent thread of information between docs. Another might need only one of those. You’re no longer forcing every session to start from a blank slate or one monolithic instruction block.
What gets better is simple. The agent stops sifting through instructions that don’t apply and only loads what matters for the task. That means individuals use tokens more efficiently, and teams can build reusable capabilities that mix and match cleanly. Less noise. More signal.
For the format itself, the Agent Skills specification is the place I’d start, and skills.sh is useful once you want to find examples to work from.
Copilot-specific layers in your agent toolbox
On that point, I use GitHub Copilot every day, so it’s worth me talking about some Copilot-specific alternatives that can also be used to package reusable knowledge. These reflect how Copilot works at time of writing, so check the GitHub docs if anything has moved on since.
Important: You don’t have to abandon
AGENTS.mdorSKILL.md. Copilot can work with those too, and you can learn more in the respective docs for AGENTS.md with Copilot and SKILL.md with Copilot.
With that, before we dig deeper into the Copilot-specific layers, let’s briefly outline what they are and how they fit together with the portable core:
.github/copilot-instructions.mdis a Copilot-native way to provide repository-wide instructions. Consider it as an alternative toAGENTS.md.*.instructions.mdfiles in.github/instructions/let you target file or path-specific instructions.*.agent.mdfiles in.github/agents/let you define specialist agent roles with specific tools, workflows, and boundaries.*.prompt.mdfiles in.github/prompts/let you create repeatable entry points for common tasks, potentially linked to specific agents.
These layers can be used together or separately. You might have a .github/copilot-instructions.md as your repo-wide baseline, and then add *.instructions.md files for specific paths, *.agent.md files for specialist roles, and *.prompt.md files for repeatable tasks. Or you might just use AGENTS.md and SKILL.md without any Copilot-specific layers at all.

*.instructions.md: optional file-scoped rules in Copilot
As we’ve seen, repository-wide instructions are a great starting point, but can sometimes be too broad.
A testing folder might have patterns that are irrelevant to the API layer. Documentation might need a completely different tone and structure than code comments. Infrastructure files may have stricter change controls than application code. That’s where path-specific instructions help.
In Copilot, you can use .github/instructions/*.instructions.md files with an applyTo glob to scope where the instructions apply. Sticking with our account settings UI overhaul example, the same pattern could look like this:
---
applyTo: "src/components/**/*.tsx"
description: Rules for React UI components
---
- Prefer existing design system primitives before creating a custom component
- Keep visible labels bound to every input
- Use `fieldset` and `legend` for grouped notification preferences
- Keep validation messages specific and next to the relevant field
The point is relevance. The agent gets the right context for the file type it’s working on, and nothing it doesn’t need. Once again, being disciplined in our token budget and providing “better context when needed” is a way to get more useful sessions.
.agent.md: optional specialist roles in Copilot
Agent files (.github/agents/*.agent.md) are useful when you want the model to take on a specialist role with clearer expertise and boundaries. Instead of one general-purpose assistant trying to do everything, you can define specialists for particular types of work: a test auditor, a documentation reviewer, a security checker, etc.
The specialist’s limitations matter as much as the expertise. A good agent file says what the specialist does and doesn’t do. That makes the behaviour more predictable and makes composition easier as each specialist has a narrower scope.
Sticking with the account settings example, while we’re intending to get more specific, I would make the specialist a bit broader than “build this one page” otherwise we’re building something too specific to be repurposed. Instead, a frontend specialist that could help across different areas of our app like onboarding, checkout, billing, and profile work, not just account settings:
---
name: Frontend Forms and Accessibility Specialist
description: Build and review product forms using existing UI patterns, accessible defaults, and realistic validation behaviour
tools: ['read', 'search', 'edit']
---
<role_boundaries>
## What You DO:
- Build and review forms using existing design system components
- Preserve labels, error states, focus management, and keyboard support
- Add or update tests for validation, submission, and edge states
## What You DON'T Do:
- Rewrite server-side auth or billing logic
- Invent a new form pattern when the design system already has one
- Change product rules without an explicit brief
</role_boundaries>
This is where the work starts to feel less like one-off prompting and more like deciding how your team wants agents to work. You decide which responsibilities belong together, where the handoffs should be, and how specialised each role needs to be.
.prompt.md: optional repeatable entry points in Copilot
I think that prompt files (.github/prompts/*.prompt.md) are probably the most task-specific. They’re a repeatable way to kick off a task. Instead of you having to write out the same prompt every time, you can have a file that acts as shortcut.
So back to our running example, the prompt that kicks off the implementation of our settings page might look like this:
---
name: implement-settings-page
description: Build or update a settings page from a design reference
agent: Frontend Forms and Accessibility Specialist
argument-hint: Link to the design or describe the settings page
---
Build or update a settings page from:
${input:design:Design link or short brief}
This might be account settings, developer settings, theme settings,
or another settings surface. You may only stop once the page, validation,
tests, and accessible states (via the `npm run test:accessibility` command) are in place. If not, consider what's missing and iterate until all requirements are met.
Chris, isn’t that just saving a text snippet? Almost, but not quite. A prompt file can reference the active file, a user-supplied input, or a specific agent to hand the task to. It’s an entry point into a defined workflow, not just a canned message. The added benefit is that once you extract a repeatable workflow into a prompt file, anyone on the team can start from the same foundation instead of improvising from scratch.
For developers, prompt files reduce the blank-page feeling. For teams, they create a shared starting point for common workflows so the quality doesn’t depend on who happens to be prompting. At time of writing, prompt files are also a Copilot feature in public preview in VS Code, Visual Studio, and JetBrains IDEs.
If you’re going deeper on the Copilot side of this, I’d bookmark GitHub’s docs on custom instructions, prompt files, and custom agents. And once you’re looking for some real-world examples, the Awesome Copilot repository, the site, and its Learning Hub are good next stops.
Choosing the right layer for your agent toolbox
None of these approaches is “the winner.” They solve different problems, and they layer rather than compete.
| Layer | Scope | Portable? | When I’d reach for it first |
|---|---|---|---|
AGENTS.md | Repo-wide guidance | Yes | I want one baseline that can travel across tools |
SKILL.md | Reusable procedure | Yes | I want a workflow that loads only when it is relevant |
.github/copilot-instructions.md | Repo-wide guidance (Copilot-native form) | No, Copilot-specific | I use Copilot heavily and want to establish a repo-wide baseline |
*.instructions.md | File or path-scoped guidance in Copilot | No, Copilot-specific | Different parts of the repo need different defaults |
*.agent.md | Specialist role in Copilot | No, Copilot-specific | I want a named specialist with particular tools, workflow, and boundaries |
*.prompt.md | Repeatable task entry point in Copilot | No, Copilot-specific | I run the same task often and want a cleaner starting command |
A repository might have an AGENTS.md for cross-tool portability, a few SKILL.md files for reusable procedures, and then Copilot-specific files layered on top for convenience. They reinforce each other, and don’t limit you to picking one or the other.
If you’re unsure which layer to start with, this flowchart may help. It is meant as a next-step guide, not a forced migration path. Remember, in Copilot, AGENTS.md and SKILL.md are perfectly valid starting points. I’ll add links to the follow-on posts in this series here as they publish:

Portability: the knowledge is the asset
One question you might be asking is “If I invest in these files, am I locking myself into a particular tool or format?” Sure, but only if you lose sight of where the value actually lies.
The valuable thing isn’t the file itself. It’s the knowledge you’ve encoded: how your repository is organised, what good looks like, where the sharp edges are, how work should be reviewed, and which specialist behaviours are worth preserving. If you move from AGENTS.md to a tool-specific instruction file, or from one agent platform to another, you’re translating rather than starting from scratch.
Some syntax may change. Some capabilities might map neatly, others less so. But in my experience, the hard bit wasn’t the schema or the format, but recognising which knowledge was worth encoding in the first place.
Treat the knowledge as the asset: your testing conventions, your architecture constraints, your do-not-do rules, your review expectations, your specific workflows and capabilities. AI (and by association, agents) are not magic. They’re tools that can help, but to do that, they need to be on the same page as you. The knowledge captured in these reusable artefacts acts as an operating manual for your agents.
The compounding effect of reusable agent context
The compounding effect is the part I find most interesting in practice, and is something I’ve noticed in my conversations with dozens of developers at different stages of building with AI tools.
Early on, sessions feel disposable. You type the prompt, get some value, move on, and next time you start again with a suspiciously similar looking prompt. But once you begin turning the repeated parts into reusable artefacts, something shifts. There’s less friction to get started. Then the session after that feels similar. You’re no longer rebuilding the same baseline from scratch.
For individual developers, this feels like building momentum. A few files of encoded knowledge become a stronger baseline for your agents. A prompt file saves you time on a recurring task. A specialist agent improves a review pass. Together, these change the experience of working with the tool.
For teams, it starts to look like shared docs and better onboarding. New joiners benefit from conventions they didn’t have to rediscover. Patterns one team has worked out become easier for another team to pick up. Even when someone else picks up the work, the starting point is still better.
The bits that help your team work better with agents are often the same bits worth publishing for others. What you clean up for your own team can become someone else’s starting point once you share it.
Equally, this is where learning in the open becomes useful. When people share their AGENTS.md files, their instruction patterns, or the way they split work across specialised agents, they’re sharing knowledge instead of keeping it in silos. That helps others recognise what’s worth encoding. You can already see that in public collections like Awesome Copilot: once people publish the reusable bits, other developers don’t have to start from a blank page. Giving back doesn’t have to mean a conference talk. Sometimes it could be a well-written instruction file pushed to a public repository that inspires another developer to do the same for their own work.
From one-off prompts to reusable agent systems
This brings us back to the thread from my post on context engineering. If context engineering is about shaping what an agent sees, reusable artefacts are the way that shaping becomes repeatable across tasks, tools, and people. And if you want multi-agent workflows, or even just cleaner handoffs between stages of work, you need to capture that knowledge in a way that is useful to agents and not left in a single useful agent session.
A planning agent needs a baseline understanding of the repository. An implementation agent needs scoped instructions and validation rules. A reviewer agent needs a different lens again. But guess what, many of those expectations are stable across tasks, and across developers working with agents in the same codebase. You don’t want to type out the same handoff instructions every time. That’s how better sessions turn into better systems.
But like anything with development, we don’t suddenly get to a perfect system. We get to a starting point, and then we iterate. Start with a single AGENTS.md file or a few SKILL.md files. See how they work in practice. Notice what you have to add to the prompt each time that isn’t already in those files. If you find yourself repeating the same instructions, or the agent isn’t quite hitting the mark, that’s a sign that something belongs in one of those reusable artefacts.
If you’ve been experimenting with any of these patterns, I’d love to hear what has ended up in your own toolbox. Drop a comment on the BlueSky thread below if you’d like to compare notes, connect with me on LinkedIn, or take a look at what I’m building on GitHub, where you’ll find working AGENTS.md files, prompt files, and agent definitions that I use day-to-day.
Until the next blog post, bye for now!
Bluesky Interactions
Comments
Related Content
Context engineering: more context isn't better context
Better prompts help, but they're only part of the story. Context engineering is the craft of designing what an AI agent sees, when it sees it, and how that changes across the session. The goal isn't a bigger context window. It's a more effective one.

Rubber Duck Thursdays - Time to build!
 GitHub
GitHub
In this live stream, we explore building a 3D tic-tac-toe visualization using Three.js and Copilot coding agent, demo MCP elicitation for gathering game preferences, and discuss the importance of context engineering when working with AI tools. We also cover GitHub changelog highlights including path-scoped custom instructions for Copilot code review and agents.md support.

Rubber Duck Thursdays - Let's build
GitHubIn this stream, Chris catches up on several weeks of GitHub updates including the remote MCP server preview and Copilot coding agent for business users. The live coding session demonstrates adding internationalization to the Copilot Airways app using Copilot coding agent, custom VS Code chat modes for planning, and agent mode in Xcode for iOS development.