The Jury Pattern: a mixture of critics for AI code review
One model reviewing its own plan tends to agree with itself. So I built a cleanup workflow shaped like a jury: separate critics from a deliberate mix of model families weigh the evidence, with a simple forcing function that keeps neighbouring reviewers off the same family. The orchestrator presides as judge, refuting rather than merging, votes promote shared findings, and a post-approval diff check can overrule a verdict that was unanimous and still wrong.
Part of: AI in Practice · Post 1 of 1 ›
- 01 The Jury Pattern: a mixture of critics for AI code review
When I first asked an agent to review its own work, the results were underwhelming. It gave the work a glowing review (of course it did, it had just written it!). Even when I ask the same model to review in a separate session, the pattern holds: a critique might surface caveats, but rarely substantial flaws or disagreement.
That’s what I hope to solve with this pattern. In human code review, we seek out someone with a different perspective because we know that someone who shares our assumptions is unlikely to catch the gaps. The same applies to models.
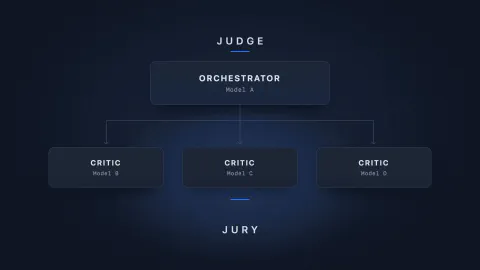
So in one of my (many) recent side projects, I deliberately pushed this a bit further and formed what I’ve named the “jury” pattern, or “mixture of critics”. A set of independent critics weigh the evidence like a jury while the orchestrator presides as the judge.
The component parts aren’t new. What’s useful is how they come together: the model that proposes the work doesn’t get to grade it. And with that, this post also kicks off a more practical series: “AI in Practice”. In this series, I’ll focus on tangible tips, tricks, patterns and workflows that I’ve found useful when working with AI. This first pattern starts with disagreement.
From a lone judge to a jury
This “mixture of critics” concept builds upon a number of well known patterns including “LLM-as-judge”, where you ask a strong model to evaluate an output and provide a score or critique. The study Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena is the reason that pattern took off. In their MT-Bench setup (non-tie votes), GPT-4 and human experts agreed around 85% of the time, while human-human agreement sat around 81 to 82%; a strong and comparable signal from the model judge.
But that number is about agreement on preference judgements between potential answers, not a universal “correctness” score. The paper also outlines limitations like position bias, verbosity bias, and even GPT-4 giving itself a higher win rate (though they call out the dataset is too limited to prove an overarching claim). Even so, it tells us something useful: a single judge can agree with humans overall and still fail in specific comparisons.
I like LLM-as-judge, but I don’t want one model to have the final word when the cost of a confident wrong answer is high. In other words, use a different model to review the work than the one that proposed it, and if you can afford to run a panel of them, even better. The review step should make the proposal defend itself before anything gets merged.
That’s why I think framing it as a “jury” pattern makes sense. I’m sure that many of us are currently asking the models to act as judge and jury at once. Instead, the critics become the jury, each weighing the evidence on its own merit, while the orchestrator is the judge who presides over them and rules on what holds up.
Anthropic captures the same instinct in their Claude Code best practices: have “a fresh model try to refute the result, so the agent doing the work isn’t the one grading it.”
In a code review, you often get better outcomes when feedback comes from developers with different backgrounds, maybe someone closer to product behaviour, someone deep in architecture or someone who has lived through past incidents. Because of our different experiences, we notice different opportunities, risks and failure modes. I think of this as “diversity of opinion”. Models from different families are trained differently, shaped by different data, and tuned for different behaviours.
I’m not saying models “think”, and I’m not treating AI output as a substitute for human judgement. I’m saying that we should vary the sources to get diversity of opinion and reduce inherent bias risk of a model.
A familiar idea, pointed at disagreement
The name Mixture of Critics is a deliberate nod to Mixture of Experts, where one model has several specialist parts under the hood and routes work between them before producing the next token. I’m borrowing the broad idea, not the mechanism.
However, Mixture of Critics applies the same intuition at a higher layer in the stack. Rather than acting in the generation of a single response, multiple models work in parallel, with a judge that challenges the outputs. The experts are whole models from different families, used to reduce potential bias. The orchestrator (or judge) then evaluates the outputs and is built to refute rather than merge.
That second change is core to this pattern. A merger averages opinions and smooths away the very disagreement and value from those differing opinions. A refuter treats each proposal as a claim to be challenged, and only what survives that challenge reaches implementation. Are there converging themes from multiple reviewers? Are there specific claims that don’t hold up to scrutiny? The refuter’s job is to find where a claim stops being true, before implementation heads down a path that won’t hold up.
This borrows from the parallelisation workflow patterns that Anthropic describes in Building effective agents: sectioning (split a task into independent subtasks) and voting (run a task several times for diverse outputs). Mixture of Critics uses both at once: one model (an orchestrator) coordinates the work, while several others tackle it in parallel. To use the analogy, the parallel critics are the jurors, each forming a view on the evidence, and the orchestrator is the judge who weighs them up and pressure-tests the findings against the standards we’ve defined.
Step through the run
This might all sound a little abstract, so let’s step through a scenario based on my own use of the pattern:
- Shipped — dead / test-only code (surfaced by GPT‑5.3‑Codex, kept by the orchestrator, confirmed on the diff)
- Refuted by the orchestrator — single-caller preset extraction: renaming, not consolidation (only one model raised it)
- Signed off, then reverted on the diff — flag-matrix duplication: every model agreed and the orchestrator promoted it, yet the actual diff shared <30% overlap for +43/+85 lines, so it was cut before commit
A real run is messier than this. The responses overlap, they come back in a different order each time, and the orchestrator is busy underneath, tracking context and spending tokens while it waits on the slower calls. I’ve folded that timing and cost away and compressed the run into nine steps you can click through at your own pace. The important piece is the shape: the cheap value check votes first, the orchestrator refutes rather than merges, and findings from critics are still verified against deterministic checks where possible.
The lineup: spread the reviewers across families
Here’s a concrete example I’ve used for clearing down semantic tech debt in a codebase, the types of cleanup that may be trickier for a linter to identify (though linters could absolutely be used as tools to help the critics do their job). In this example, the orchestrator runs on Claude Opus 4.7 and selects a jury of workers (each on a different model):
| Role | Model | Job |
|---|---|---|
| Orchestrator | Claude Opus 4.7 | Dispatch the panel, synthesise, refute and promote findings, inspect the final diff, commit |
| Critic A | GPT-5.3-Codex | Suspected dead code paths and test-only helpers |
| Critic B | Claude Sonnet 4.6 | Drift from architectural principles |
| Critic C | GPT-5.5 | Structural duplication |
| Implementer | GPT-5.3-Codex | Ship the file edits |
The diversity is encouraged in the prompt, and it’s scoped to the critics on purpose. I avoid putting neighbouring reviewers on the same model family as a simple forcing function. It doesn’t make the panel independent; it just stops the lineup becoming three near-identical calls unless I explicitly call that out as a pre-condition. The implementer ships the change and sits outside the panel, in other words, whichever model is efficient at taking the plan and acting upon it. That could be a model we’ve already used, because it’s not acting as a critic.
If I run this pattern across a few tasks and the mixed-family critics keep agreeing with the original proposal without finding anything new, I treat that as a warning. Either we’re genuinely on the right track, or the critics aren’t pushing hard enough. Most of the time, I suspect the second.
Three shapes, one rule: never grade your own work
That lineup of one orchestrator and three critics (who were effectively acting as architects) is one concrete approach to the pattern. It’s easy to get hung up on which models I picked, but they’re just an implementation detail. The more important part is the structured review process we’re building: keep whoever proposes the work separate from whoever grades it, and you can run that same idea in a few different shapes depending on what you want to learn from the disagreement.
| Sub-pattern | Example | Strengths | Limitations |
|---|---|---|---|
| Persona-based divide and conquer | Three critics with different roles: dead-code hunter, architecture reviewer, threat modeller | Broad coverage across domains, clearer division of labour, useful when you need depth in different areas at once | Harder to isolate model effects because role and model can both influence the result |
| Parallel cross-model divide and compare | Same task, same prompt, same context across multiple model families | Cleaner read on model-family differences, easier to spot where one family’s reasoning diverges, strong for pressure-testing a finding | More latency and cost as model count grows, can produce repetitive findings if prompts are too similar |
| Hybrid role-and-family split (bonus third) | Two role tracks (e.g. architecture and security), each run across two model families in parallel | Best coverage when risk is high, balances domain depth with model-diversity checks, stronger signal when findings converge across both role and family | Highest cost, coordination overhead and potential latency. Consumes many more tokens given the expansive combination and may need tighter stopping rules to avoid analysis loops |
Which one I use comes down to risk and intent:
- Looking for domain coverage? Split by persona.
- Looking for a cleaner bias check? Split by model family.
- Need both? Run a hybrid.
Two gates: refute first, diff-check last
When the jury reports back, the judge checks each proposal against a short list of rules the codebase treats as non-negotiable and marks violations as refuted before it reaches me as the human in the loop.
Take a critic proposing that several sets of config values get pulled into a shared preset and start with a practical question: are these call sites really sharing behaviour, or do they just have the same shape? The lightweight “mechanical” check comes first, partly because it’s cheaper. Use tools like linters, existing scripts, or small pieces of automation to compare the values side by side. If too few of them overlap, the proposal is probably noisy rather than a good candidate for consolidation, and the orchestrator refutes it on the spot. We handle a single-caller extraction similarly because that’s essentially renaming rather than extraction or consolidation.
If a proposal fails there, I don’t need to spend model tokens asking a critic to reason about it. The harder question which the mechanical tools may not be able to answer is whether those values are doing the same job in each place, and that’s where the model can help.
When more than one juror independently flags the same file, I move it up the backlog, but I still treat it as a signal, not a verdict. That lines up with the instinct behind Self-Consistency Improves Chain of Thought Reasoning in Language Models, where sampling one model several times and taking the consensus answer can beat trusting a single pass. Agreement is a triage insight, but the scrutiny still has to happen.
Even a confident jury can still be wrong, so I don’t stop at the verdict. OpenAI’s LLM Critics Help Catch LLM Bugs found that model-written critiques were preferred over human critiques 63% of the time in their setting, but the models could still invent bugs. The study found that pairing the critic with a human reviewer was the strongest setup.
However, in the last round of the jury pattern, I have a final gate that can overrule the verdict: the diff check. After the implementer finishes, the orchestrator reads the actual diff against what the proposal promised. If a change isn’t achieved (e.g. it claims to remove lines and adds them instead), it fails.
Consider this as a final sanity check. The jury can be confident, but if the change doesn’t actually do what it said it would, that’s a problem. The diff check is a safety net to catch any issues that slipped through the jury’s scrutiny, whether due to model limitations or just an honest mistake in implementation.
The strongest objection to all of this
Walden Yan’s Don’t build multi-agents argues that parallel agents work off partial context and make conflicting implicit decisions that fall apart when you merge them:
Actions carry implicit decisions, and conflicting decisions carry bad results.
I think they’re right about the failure mode, but this pattern is set up a bit differently. Each critic is looking at a slice on purpose, so the limited context matters less here. The critics are read-only: they propose and refute, they never independently edit. They all reason over the same shared non-negotiables as ground truth. And the orchestrator refutes rather than merges, so conflicting assumptions get argued out before a single line is written. Cognition’s warning is about uncoordinated agents that act. Here the jury argues, the judge rules, and then one hand implements.
Chris, isn’t a swarm of premium models just an expensive way to do a code review? It’s more expensive, and that’s a fair objection. It’s a handful of premium model calls per run, cheap on a targeted file and uncomfortable across a whole codebase, and the token spend swings with the model mix and how many critique loops you allow. So I don’t run it on every change. I typically use the jury pattern when a confident wrong refactor would cost more to unwind than the calls cost to avoid. Cap the rounds, set clear exit criteria and escalate when confidence keeps bouncing without converging.
The skill, in its own words
The skill is fairly light, as the wider conventions and instructions are already in place in the repository. It might look something like this:
---
name: mixture-of-critics
description: Review a file for semantic tech debt with a jury of
mixed-model critics that argue toward a fix. The orchestrator refutes
proposals rather than merging them, and a post-approval diff check can overrule a
unanimous verdict. Use when one model's self-review keeps rubber-stamping its own
plan, or when a confident-but-wrong refactor would cost more to unwind than the
model calls cost to avoid. Skip it for routine changes; this is for risky ones.
---
# Mixture of Critics
## Core procedure
1. Spread the delegation across model families. Keep adjacent reviewing roles on
different families. The implementer ships the edits and sits outside the panel.
2. Dispatch each architect (subagent) to its own domain in parallel. Critics are read-only:
they propose and refute, they never edit.
3. Refute, don't merge. Treat every proposal as a claim to challenge, and check it
against the codebase's numbered non-negotiables first. Mark anything that breaks one
`refuted` before a human sees it.
4. Promote on agreement. A file flagged independently by two or more architects is
a higher-confidence target, so move it up the backlog.
5. Run the diff check before commit. Read the real diff against what the proposal
claimed. If a change billed as removing lines instead adds them, revert.
## Example prompt controls
- "Run at most two critique rounds per file, then escalate to human review."
- "For debt-only cleanups, stop if the patch adds net new production code."
- "If confidence is still split after round two, stop and ask for a human decision."
- "If any numbered non-negotiable is broken, reject the proposal in this pass."
- "Set a token budget per stage, and report any budget overrun before continuing."
## Gotchas
- A model told to critique will produce polite agreement with caveats. The
non-negotiables have to be concrete and numbered before `refuted` means anything.
- Apparent duplication is often coincidence. Compare the real values before
extracting shared config. In that repo, I used 60% as a rough tripwire, not a
universal rule. The point is to force a cheap comparison before model reasoning;
a single-caller extraction is renaming, not consolidation.
- Cost is sensitive to roster and loop depth. Keep explicit stopping criteria,
cap critique rounds, and set a per-stage token budget so downstream agents
don't run indefinitely.
- A unanimous verdict is not proof. The diff check exists because one was unanimous
and still wrong.
The gotchas are hints to help the agent understand the common failure modes and how to avoid them. They won’t cover every possible issue. Their job is to discourage easy agreement and push the model to challenge proposals with concrete checks.
Start with one critic
If you’re getting started with AI and agent judge patterns, you don’t need to start with a jury. You can start with one critic on a different model family from the one that wrote the plan, with explicit permission to disagree.
But if you want to push into the jury pattern, the most important part is the separation of responsibilities. The critic, the orchestrator and the implementer each have to be able to act without being overruled by the same model that proposed the plan.
We’ll explore more of the practicalities and considerations in future posts. Before then, if you’ve been running multi-model setups, I’d love to know whether you’ve found that model disagreement helps or just adds noise, and how you decide which voice wins when they disagree. Come and argue (see what I did there? ;)) with me on the Bluesky thread below, or reach out on LinkedIn.
Bluesky Interactions
Comments
Related Content
Agentic memory: what agents should and shouldn't remember
Conversation state and retrieved context lead naturally into memory, but only if we're clear about what memory is for. Rules, skills, and instruction files package what you already know. Memory should capture what the work itself teaches the system, and that means reflection, verification, and forgetting matter just as much as recall.
Context engineering: more context isn't better context
Better prompts help, but they're only part of the story. Context engineering is the craft of designing what an AI agent sees, when it sees it, and how that changes across the session. The goal isn't a bigger context window. It's a more effective one.

Rubber Duck Thursdays - Time to build!
 GitHub
GitHub
In this live stream, we explore building a 3D tic-tac-toe visualization using Three.js and Copilot coding agent, demo MCP elicitation for gathering game preferences, and discuss the importance of context engineering when working with AI tools. We also cover GitHub changelog highlights including path-scoped custom instructions for Copilot code review and agents.md support.